以TPU v6e-8为例子,每个容器切分到的chip数量只能是1,4,8,也就是二的整数次幂。
如果你要部署5个服务,那么可以部署成1个服务分配4个chip,4个服务部署1个chip的形式。
JAX讨论 QQ群:771728973
以TPU v6e-8为例子,每个容器切分到的chip数量只能是1,4,8,也就是二的整数次幂。
如果你要部署5个服务,那么可以部署成1个服务分配4个chip,4个服务部署1个chip的形式。
# 安装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 克隆sglang-jax
git clone https://github.com/sgl-project/sglang-jax
cd sglang-jax
# 安装sglang-jax
uv venv --python 3.12 && source .venv/bin/activate
uv pip install -e "python[all]"
下载权重到 /dev/shm 内存盘
uv run python -u -m sgl_jax.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --trust-remote-code --dist-init-addr=0.0.0.0:10011 --nnodes=1 --tp-size=4 --device=tpu --random-seed=3 --node-rank=0 --mem-fraction-static=0.8 --max-prefill-tokens=262144 --download-dir=/dev/shm --dtype=bfloat16 --skip-server-warmup --host 0.0.0.0 --port 30000
拷贝权重到gcs
gcloud storage cp -r /dev/shm/model--【模型名称】 gs://【gcs目录】gcsfuse 【桶名称】 /【挂载路径】本教程使用 Qwen/Qwen3-235B-A22B-Instruct-2507
节点0
JAX_COMPILATION_CACHE_DIR=/dev/shm/jit_cache uv run python -u -m sgl_jax.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --trust-remote-code --dist-init-addr=0.0.0.0:10011 --nnodes=2 --tp-size=8 --device=tpu --random-seed=3 --node-rank=0 --mem-fraction-static=0.8 --max-prefill-tokens=262144 --download-dir=/【挂载目录】 --dtype=bfloat16 --skip-server-warmup --host 0.0.0.0 --port 30000 --page-size 16节点X(X>0)
JAX_COMPILATION_CACHE_DIR=/dev/shm/jit_cache uv run python -u -m sgl_jax.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --trust-remote-code --dist-init-addr=【节点0 IP地址】:10011 --nnodes=2 --tp-size=8 --device=tpu --random-seed=3 --node-rank=1 --mem-fraction-static=0.8 --max-prefill-tokens=262144 --download-dir=/【挂载目录】 --dtype=bfloat16 --skip-server-warmup --host 0.0.0.0 --port 30000 --page-size 16
OpenAI Compatible 格式连接到 http://【节点0】:30000/v1即可
us-docker.pkg.dev/cloud-tpu-images/inference/jetstream-http:v0.2.2 对应的github路径是ai-on-gke项目的tutorials-and-examples/inference-servers/jetstream/http-server
us-docker.pkg.dev/google-samples/containers/gke/gradio-app:v1.0.3对应的是GoogleCloudPlatform/kubernetes-engine-samples项目的ai-ml/llm-serving-gemma/gradio
us-docker.pkg.dev/cloud-tpu-images/inference/maxengine-server:v0.2.2对应的是AI-Hypercomputer/maxtext项目 以及 ai-on-gke项目的tutorials-and-examples/inference-servers/jetstream/maxtext/maxengine-server
尽量使用us-west1 / us-cetrnal1 / us-east1 的e2-micro规格VM,附加30GB standard persistent disk,不要使用premium网络,选择Standard可以享受免费200GB流量. VM可以用来部署反向代理,TPU自动化抢占等任务,任务尽量和VM是同一区域的。
CDN选择CloudFlare接入,如果选择了Standard网络会先使用200GB免费流量,根据GCP CDN interconnect从US拉费用最低能够到0.05 USD /GB
鉴权/IAM系统选择FireBase Authentication免费接入。
选择Cloud Run作为Serverless提供API服务,Cloud Run免费提供两百万次操作,三十六万 GB * s(秒) 内存,十八万 vCPU * s(秒),同区域内网通信没有网络费用
API Gateway服务聚合各项Serverless服务,两百万次操作内免费,同区域内网通信不收网络费用
数据库选择Cloud Firestore NoSQL数据库,1GB存储免费,同区域内网通信不收网络费用
队列系统采用Cloud Tasks,前一百万条请求不收费
看你白嫖能力了,上不封顶,目前最高记录国外科研团队白嫖到了8960个TPU v4
安装gcsfuse
(sudo NEEDRESTART_MODE=a bash || bash) <<'EOF'
apt update && \
apt install -y numactl lsb-release gnupg curl net-tools iproute2 procps lsof git ethtool && \
export GCSFUSE_REPO=gcsfuse-`lsb_release -c -s`
echo "deb https://packages.cloud.google.com/apt $GCSFUSE_REPO main" | tee /etc/apt/sources.list.d/gcsfuse.list
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
apt update -y && apt -y install gcsfuse
rm -rf /var/lib/apt/lists/*
EOF挂载
gcsfuse --implicit-dirs --file-cache-max-size-mb=32768 --cache-dir=/tmp 存储桶名称 /tmp/gcsfuse加载保存的F5镜像
docker load -i /tmp/gcsfuse/f5/f5_image.tar启动镜像
docker run \
--net=host \
--privileged \
-v /tmp/gcsfuse:/bucket \
f5_image:dev \
python -m src.maxdiffusion.f5_gradio_ui_load_aot /bucket/f5/f5_docker.yml第一步,申请一个TRC账户
第二部,写一个自动化脚本去开v6e和v5p的TPU spot机器
白嫖地区一览:v6e(最先进的推理TPU):asia-northeast1-b us-east1-d eu-west4-a us-east5-b
v5p(最先进的训练TPU):us-east5-a us-central1-a
首先克隆源代码
git clone https://github.com/vllm-project/vllm.git
在每个worker上安装依赖
cd vllm && pip install -r requirements/tpu.txt
安装库
sudo apt-get update && sudo NEEDRESTART_MODE=a apt-get install libopenblas-base libopenmpi-dev libomp-dev -y
安装vllm
cd vllm && VLLM_TARGET_DEVICE=”tpu” python setup.py develop
开启ray头节点
ray start –head –port=6379
其他worker连接头节点
ray start –address=’xx.xx.xx.xx:6379′
启动openai兼容api server
python3 -m vllm.entrypoints.openai.api_server –host=0.0.0.0 –port=8000 –tensor-parallel-size=芯片数量(4或8 由于有40个head因此此选项只能说4或8) –model=Qwen/QwQ-32B –trust-remote-code
使用ray的多节点需要开启 –distributed-executor-backend ray
如果100G空间不够使用gcsfuse挂载和开启 –download-dir=/xxx/bucket/
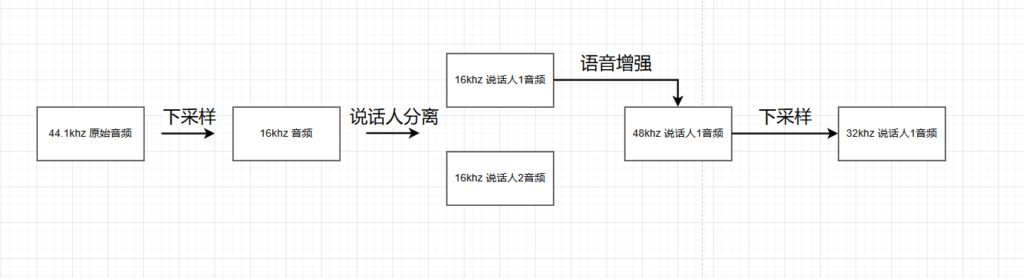
设想的工作流
实际
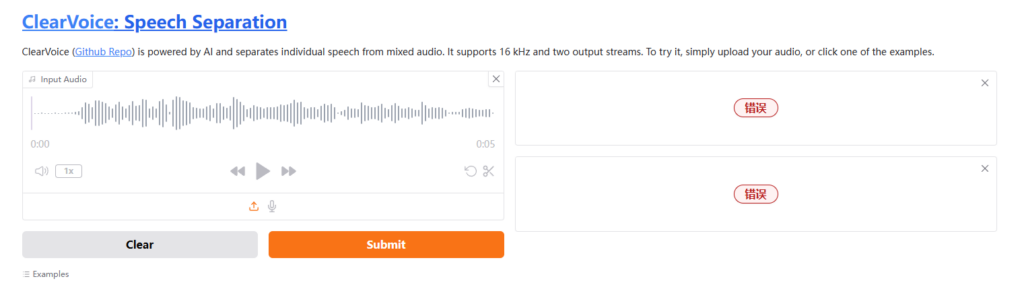
hf demo都炸了,没人管的说是
Diffusion TTS如F5-TTS拥有强大的zero-shot能力,能够很好的模仿参考音频的节奏和音色,可控性极强,生成速度快,但是算力要求巨大。
基于Continuous Token的AR TTS模型,如Mell-E ,算力要求在Diffusion和离散AR之间,属于一种折中选择。
基于Discrete Token的AR TTS模型,如VALL-E,训练要求很高,需要大量数据进行训练,推理性能要求最低。
如果我们能够使用一个Diffusion TTS模型,或者一个AR + Diffusion的混合模型作为teacher模型,利用算力合成大量优质的音频。
用一个算力要求较低的NAR或者AR模型作为student模型,学习teacher模型的优秀性能。就能够实现用较低算力合成优质的音频。
项目地址: https://github.com/flyingblackshark/MaxTTS-Mel.git
实现了Mel输入和采样
难点:
优点: