项目设置里面勾选 权限(角色)断言 和 验证时检查授权
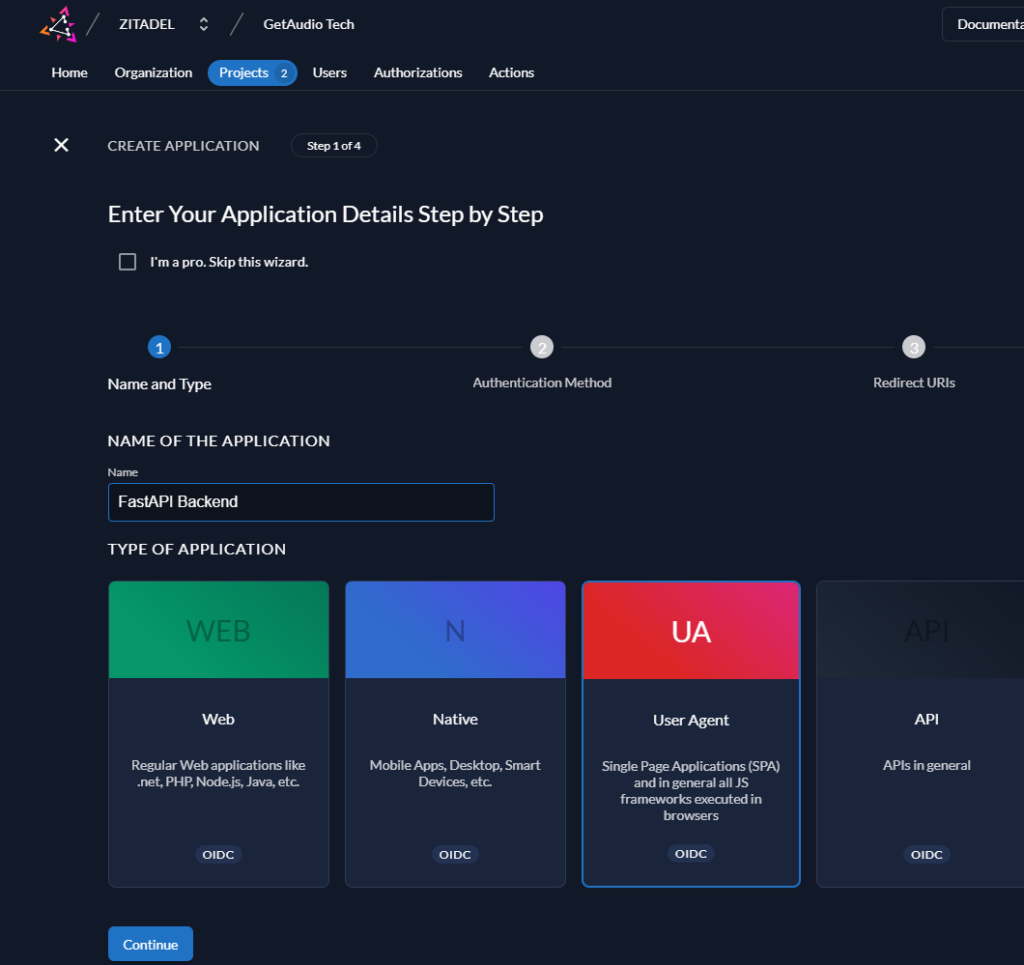
类型选择User Agent,命名为FastAPI Backend
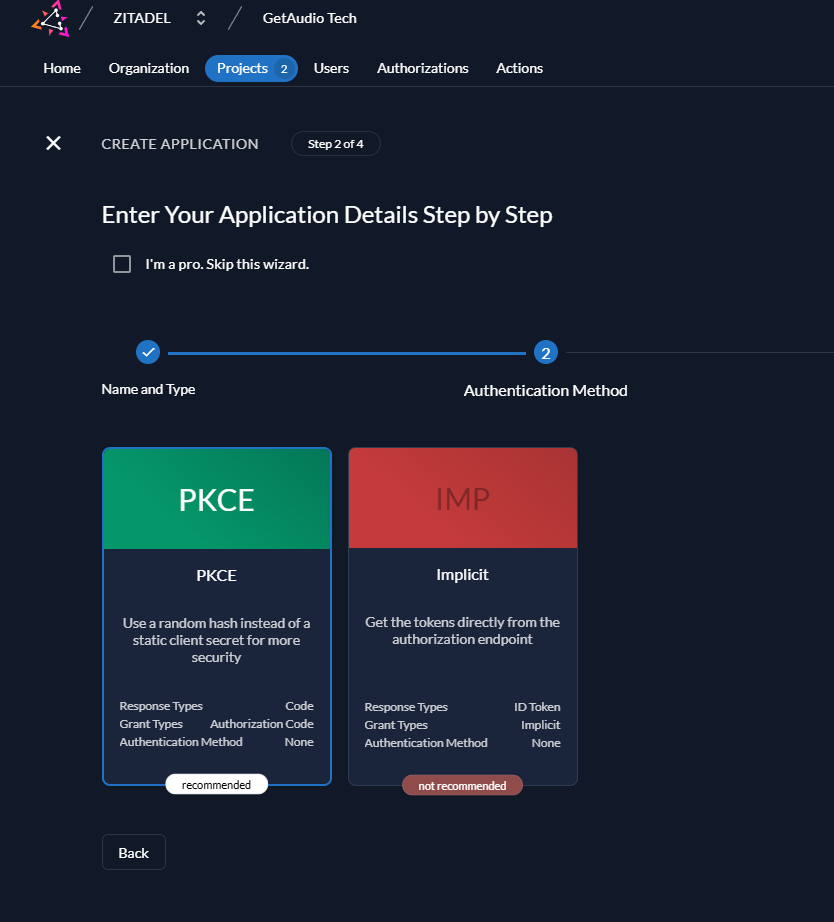
验证类型选PKCE
回调地址可填写可不填,如果不需要让客户错误访问后端时跳转就不填

将Token类型选择为JWT,勾选权限写入Token
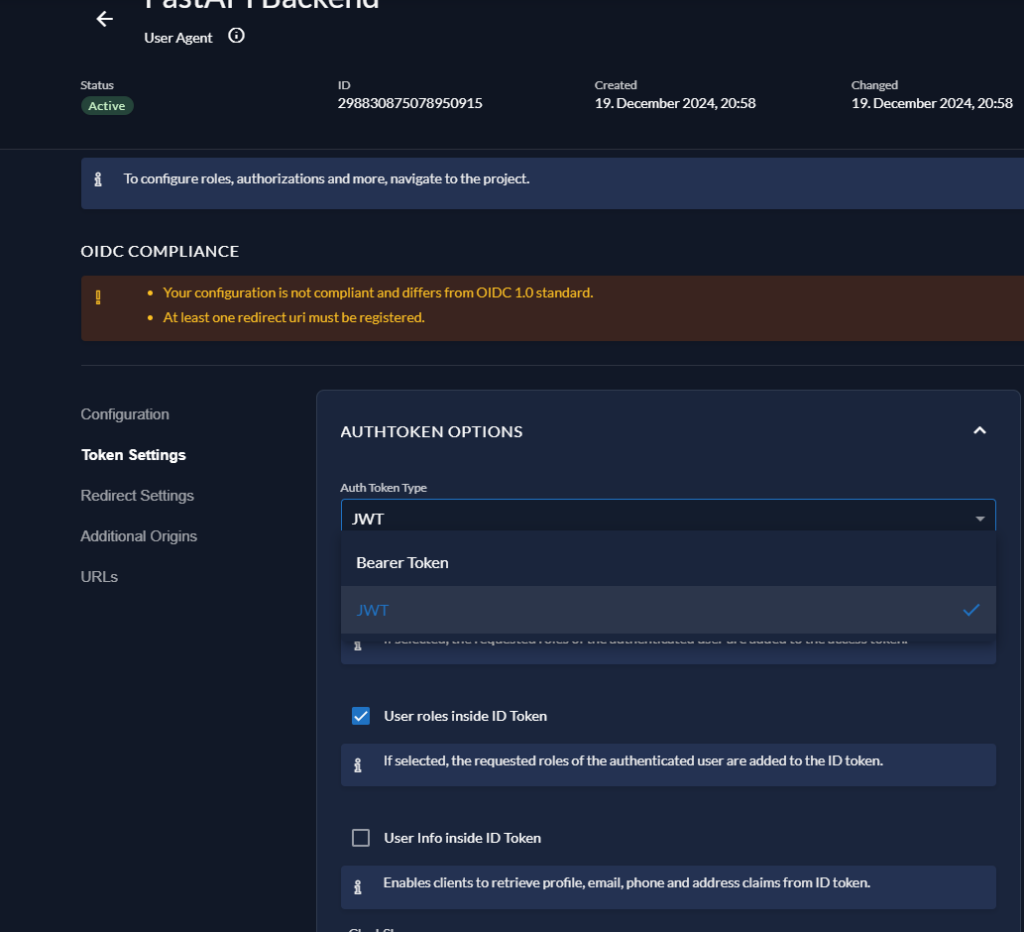
由于我们只是拿前端JWT做校验,所以不符合OIDC标准也无所谓
JAX讨论 QQ群:771728973
项目设置里面勾选 权限(角色)断言 和 验证时检查授权
类型选择User Agent,命名为FastAPI Backend
验证类型选PKCE
回调地址可填写可不填,如果不需要让客户错误访问后端时跳转就不填
将Token类型选择为JWT,勾选权限写入Token
由于我们只是拿前端JWT做校验,所以不符合OIDC标准也无所谓
创建一个项目
创建一个应用起名 NextJS Frontend
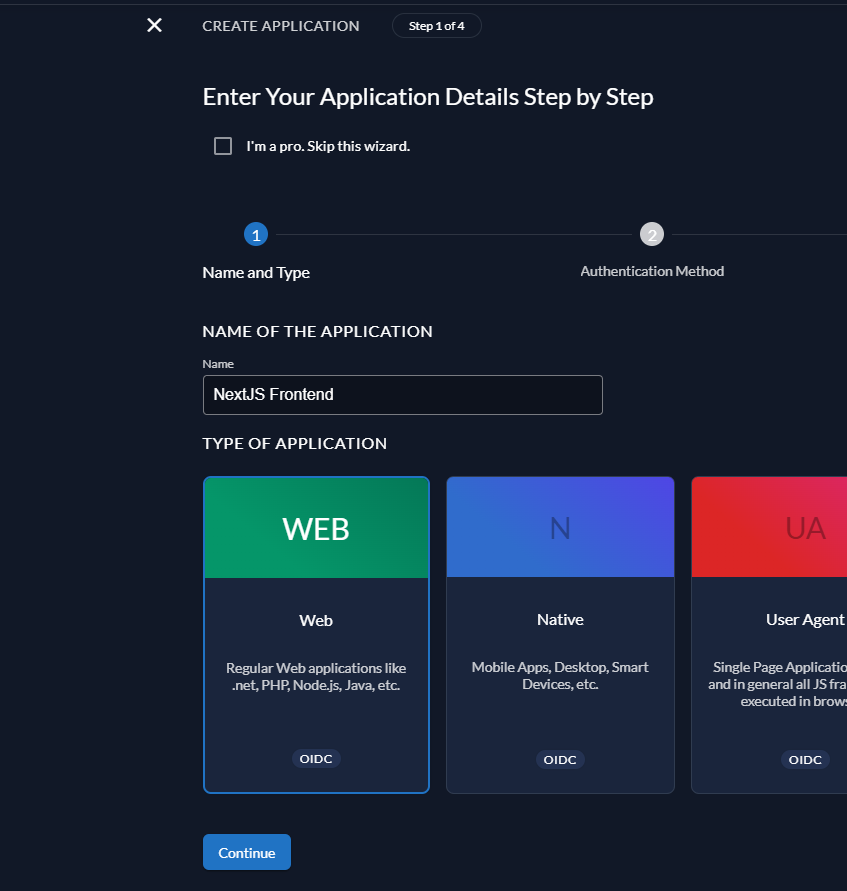
验证方式选择Code
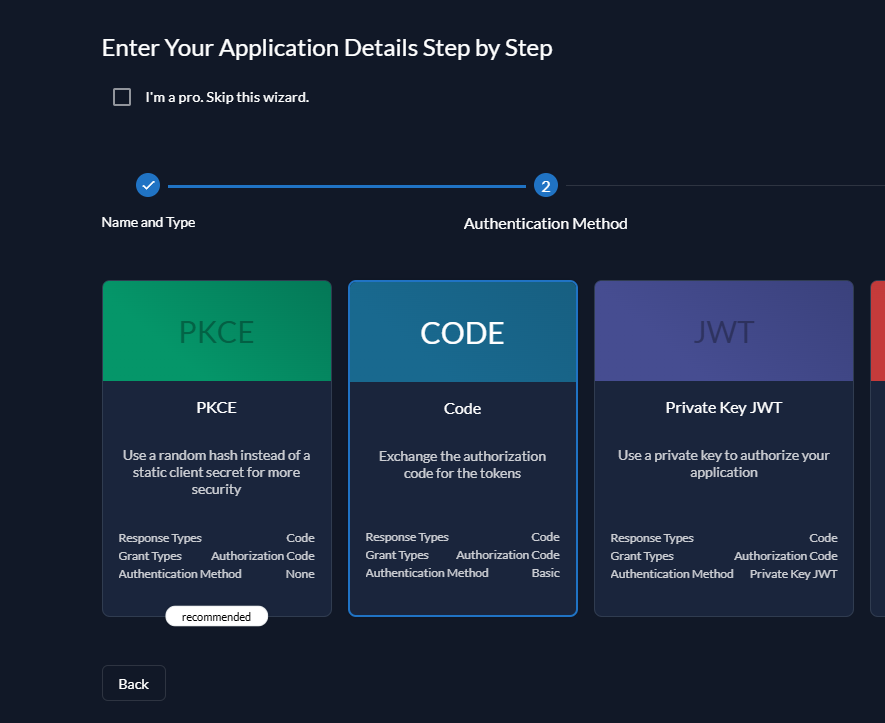
添加开发回调和生产回调
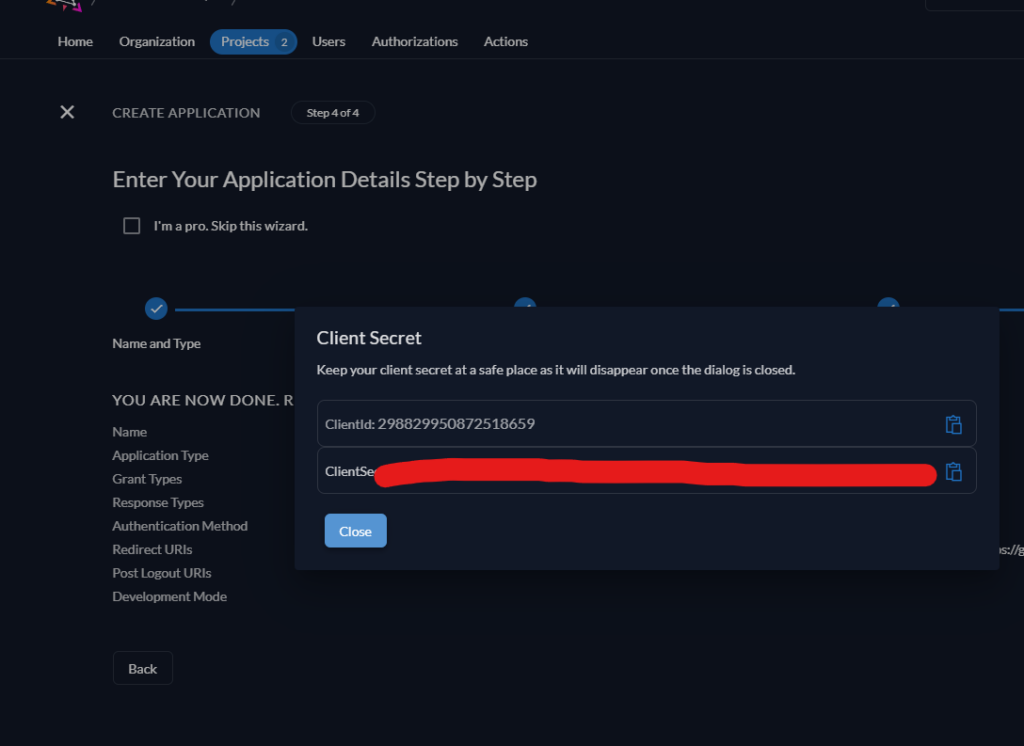
记录ID和密钥
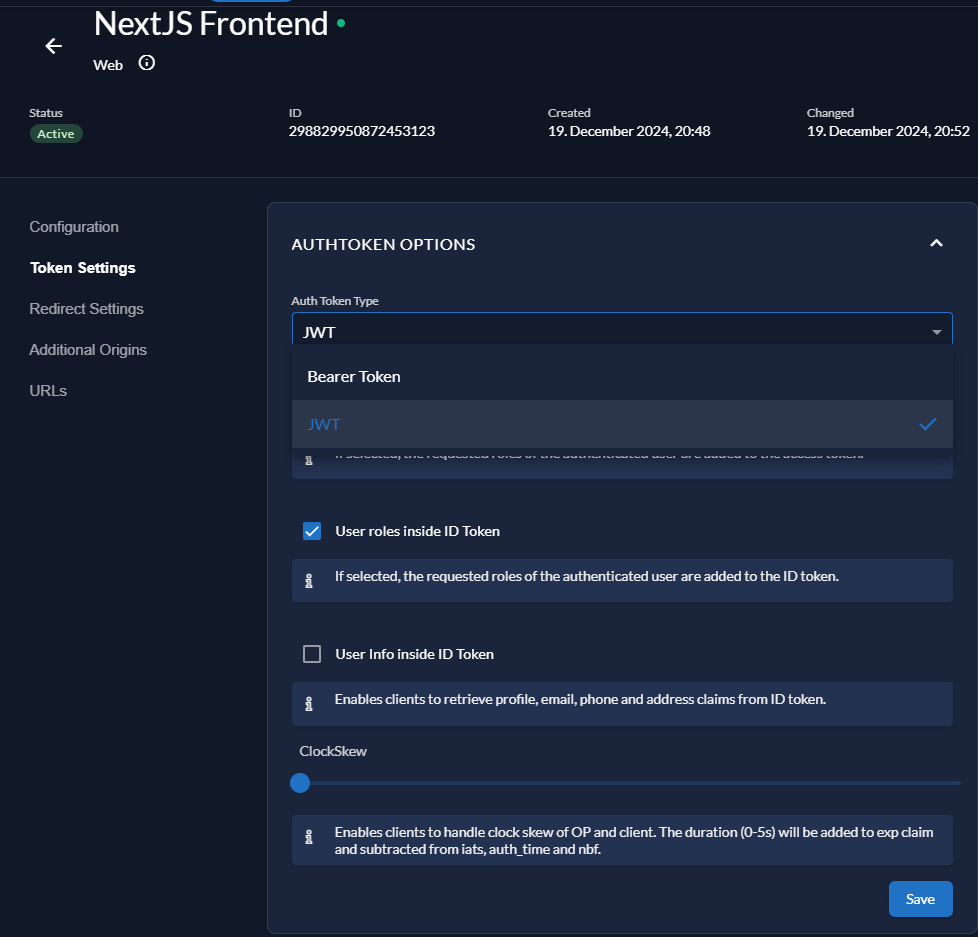
修改Token类型为JWT,并将用户权限信息写入JWT,方便访问其他项目时进行验证
背景:由于我们需要使用Grain 作为我们Dataloader,因此我们需要使用Grain支持的格式,如ArrayRecord / HuggingFace(Paquet) 等二进制格式。
使用Grain 从HuggingFace上的 MikhailT/hifi-tts 数据集读取数据,读取其中的audio列和text_normalized列进行处理。
首先用Fish Speech Tokenizer对text_normalized进行转化,将其转化成Tokens。然后经过Grain的Operations处理后形成Batch读入,利用TPUv4通过声码器进行批量提取,将其转化成音频Tokens。
随后利用循环逐个处理,将文本Tokens拼接上已经转为Tokens的前缀和后缀,表示user输入,然后拼接上音频Tokens表示assistant输出。这样就可以方便的输入LLM进行训练
舒缓的电子音乐,配合AURORA令人放松的人声,让人似乎逐渐走进一个迷人的夜晚,月光下的树影中有一位迷人的仙子在歌唱。
灵动的电子乐,音乐节奏恰如心脏的泵动,让人感到莫名的欣快。
中规中矩的电子乐,伴随着轻松的弦乐,配合MV看还不错。
舒缓的电子乐,中规中矩,感觉氛围营造上面不如第一首。
从开始的舒缓逐渐加快,中间爆发的高音仿佛直达了天堂。
弦乐主导的一首曲子,听感一般,人声从平静到爆发的过度不太自然。
节奏较快的一首歌曲,开始有一种庄严感,过渡到一种紧迫感,最后爆发。
节奏明快的一首电子乐,感觉作为游戏配乐很合适,和声很好听。
Remix版好听
本专辑最好听的一首歌,仿佛躺进了棉花糖里面,感觉身体逐渐失去了重力,真的进入了一场梦。弦乐和鼓营造了极佳的氛围感,人声的高音恰到好处,没有太尖锐而是平缓的转音。
开头添加了一些Glitch音,构造了一种混乱的感觉,其中古筝的声音又有一种和谐的感觉,构造了一种混乱与和谐碰撞的感觉。
FX音效和响板的声音很突出。后面听着像Disco音乐
超级大爆,Hard Bass一出来直接提神醒脑。
作为游戏音乐的潜力很大,节奏感超强。仿佛手里拿着刀锋的女武神站在你面前。
有一点pop音乐的感觉,还不错。
感觉站在光芒下面,弦乐的声音舒缓释放,AURORA的声音抚慰人心。
简评: AURORA歌曲的又一个巅峰
强劲的北欧电音
纯净的人声,绝美的低音区
来自挪威森林的自然之音
组成了一个完美的有机整体
Your Blood:AURORA风格大转变,歌曲整体似乎过于平淡了,歌词中规中矩.电音和人声的配合不太好,高音甚至有点刺耳,听感不是很好.MV很廉价也很迷惑,感觉拍的一般.
The Conflict of The Mind:比Your Blood听感稍好,这首歌的Lead音色能更好衬托出AURORA的人声.MV比Your Blood的稍好,氛围感很好.

这是继新Era首发曲子Your Blood之后的第二首曲子,据称新歌曲名称为这首歌的名字会是 “Conflict In Mind”. 让我们一起期待AURORA新歌曲的表现!
利用docker配置Zitadel认证服务容器Caddy反向代理容器以及Netbird相关容器
export NETBIRD_DOMAIN=[此处填入网站域名];
curl -fsSL https://github.com/netbirdio/netbird/releases/latest/download/getting-started-with-zitadel.sh | bash如果需要与其他网站容器共存,修改Caddyfile,填入域名并配置反向代理和证书
输入你填入的网站域名,进入管理面板

登录容器创建结束后打印出来的管理员账户,进入面板

选择Setup Keys

创建一个Key使得机器可以加入全互联网络

在CLI模式下可以输入
netbird up --setup-key [刚才生成的Key XXX-XXX-XXX] --management-url [设置的域名]Windows下把Netbird客户端设置内的Management URL改为你设置的域名,然后点击登录,会跳转到登录页,登陆后即可加入全互联网络.
要求:英伟达显卡(NVIDIA GPU)
第一步 下载Whisper-UI
下载 https://github.com/jhj0517/Whisper-WebUI/archive/refs/heads/master.zip 并解压

第二步 安装
在Windows商城里面安装Python
右键选择“在终端中打开”

输入 pip install -r requirements.txt

启用OpenAI Whisper v3 语音识别模型
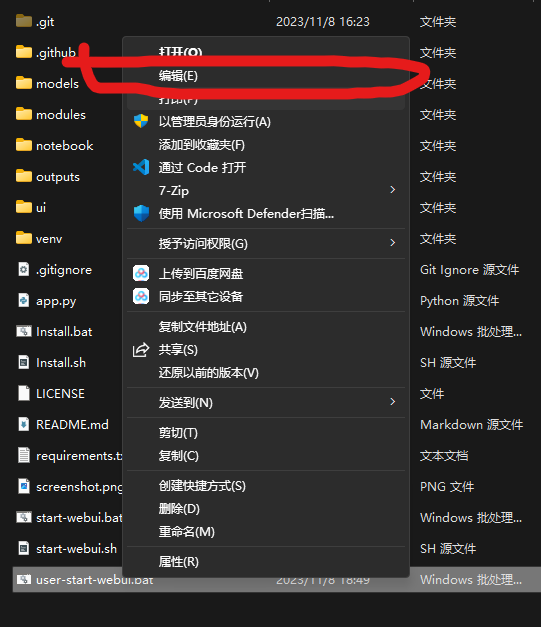
右键user-start-webui.bat 选择“显示更多选项”

点击”编辑“
set下方添加一行set DISABLE_FASTER_WHISPER=true

第三步 运行
双击 user-start-webui.bat 运行WebUI

模型选择large-v3

将视频或音频文件拖入即可

最后点击Generate开始识别音频


【1】处可查看结果和路径 点击【2】处可以跳转到字幕文件生成的目录



